Causal Quartets
On this weeks episode of Casual Inference we talk about a “Causal Quartet” a set of four datasets generated under different mechanisms, all with the same statistical summaries (including visualizations!) but different true causal effects.
The figures and tables are from our recent preprint: https://arxiv.org/pdf/2304.02683.pdf 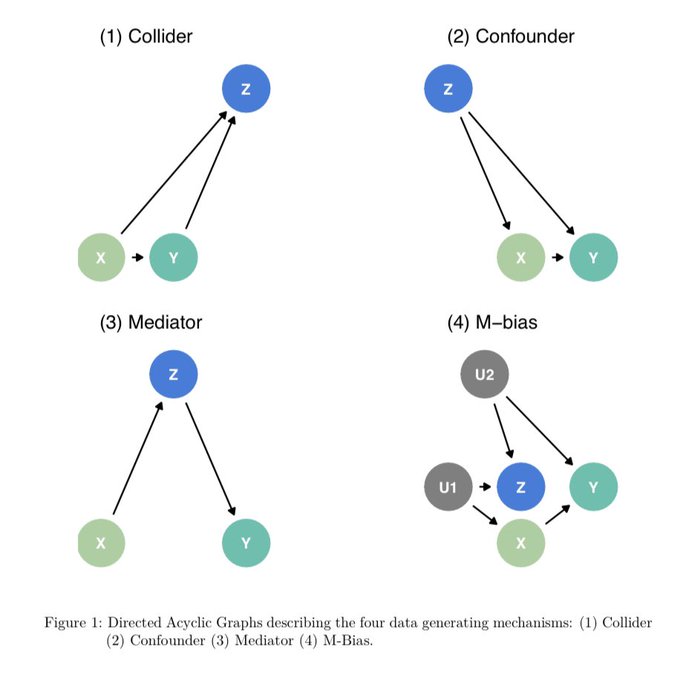
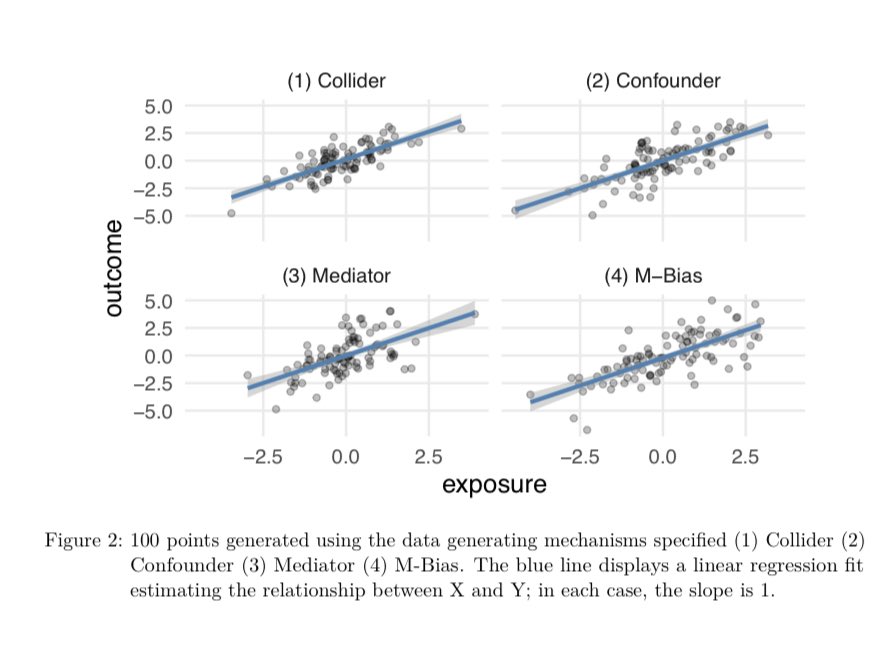
Given a single dataset with 3 variables: exposure, outcome and covariate (z) how can statistics help you decide whether to adjust for z? It can’t! For example here, the correlation between z and the exposure in all 4 datasets is 0.7!
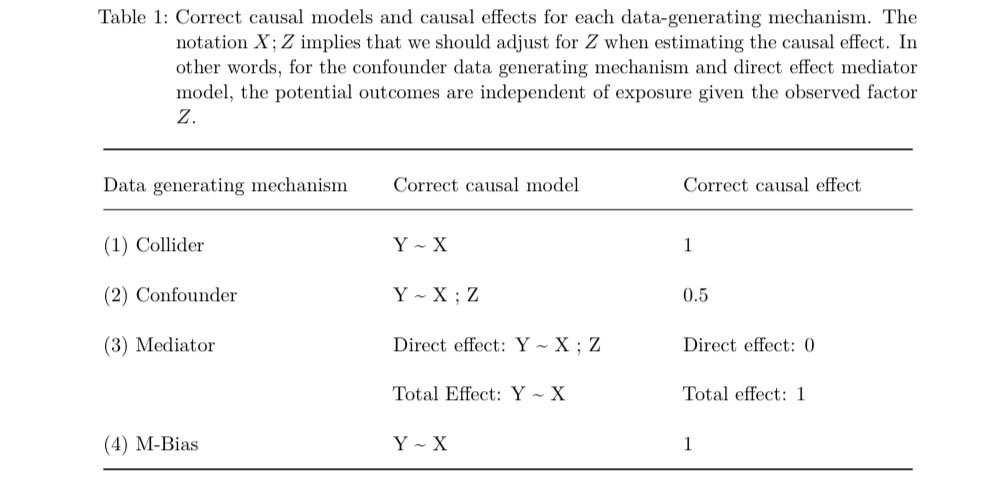
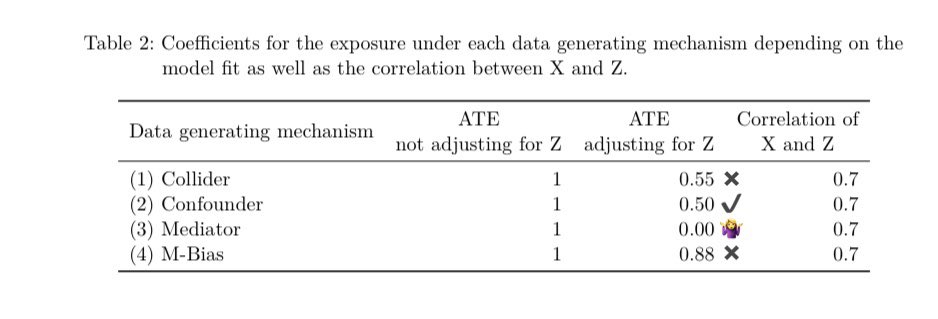 So if Stats can’t help what can we do? Well the best thing is just to know the data generating mechanism but that is hard! An easier solution is to make sure to have time varying measurements and only adjust for pre-exposure covariates! This solves the problem in 3/4 of the sets!
So if Stats can’t help what can we do? Well the best thing is just to know the data generating mechanism but that is hard! An easier solution is to make sure to have time varying measurements and only adjust for pre-exposure covariates! This solves the problem in 3/4 of the sets!
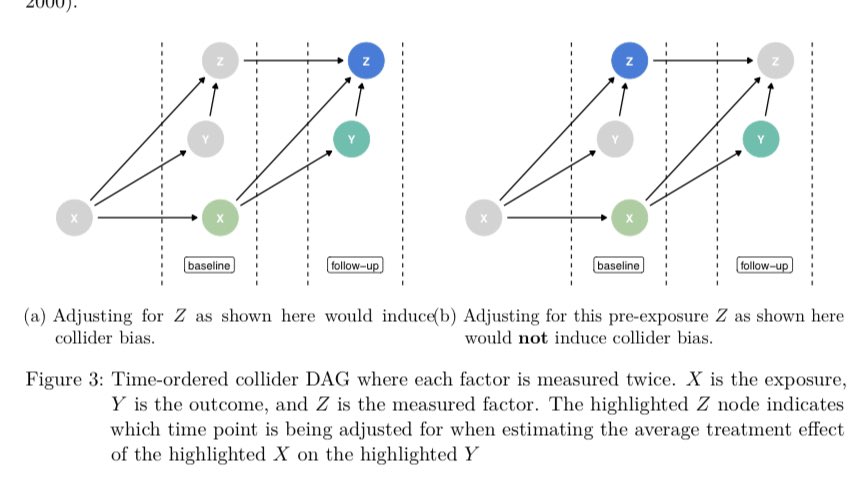
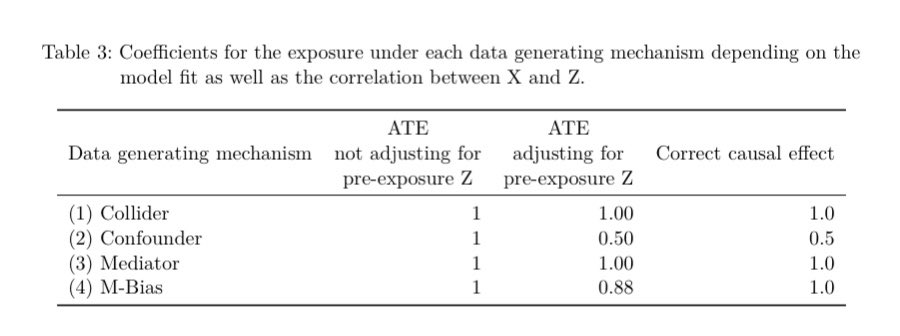
The one it doesn’t solve is M-bias, but as our podcast episode title suggests (M-Bias: Much Ado About Nothing?) this may be much ado about nothing (give a listen to find out why!) Also…credit to ChatGPT for our episode title 😂
Malcolm Barrett, Travis Gerke, and I have a preprint with details: https://arxiv.org/pdf/2304.02683.pdf
Also the quartets package includes the datasets if you’d like to play with it yourselves!
I also learned last month about another awesome “causal quartet” by Gelman, Jessica Hullman, and Lauren Kennedy that focuses on treatment heterogeneity so I could use help coming up with a new name for ours!